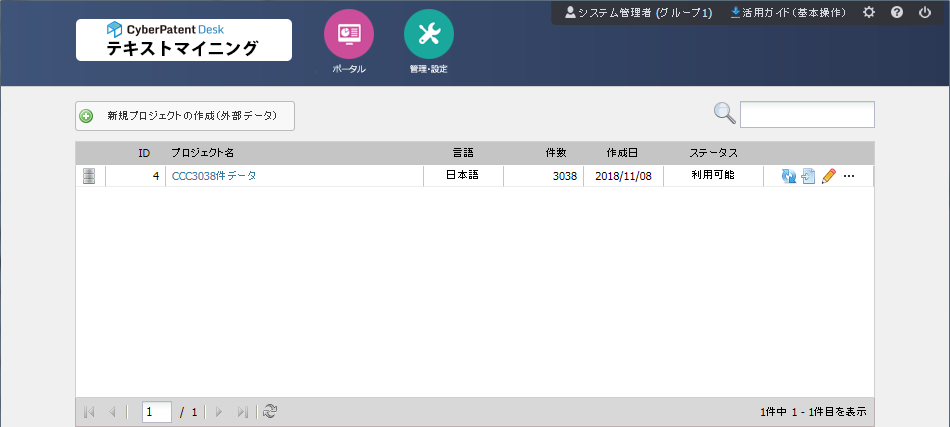
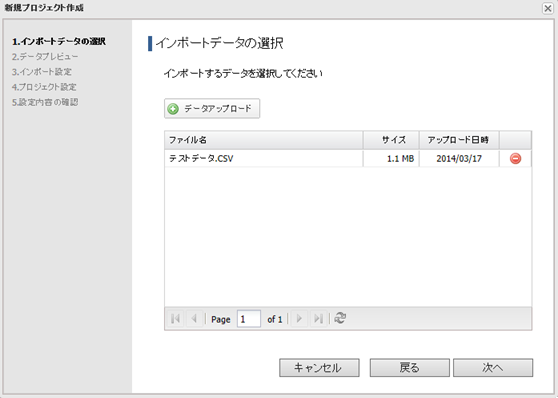
1.[新規プロジェクトの作成]ボタンをクリックすると表示します。
ファイルを選択して[次へ]ボタンをクリックします。
データをアップロードする場合は[データアップロード]ボタンをクリックします。
![]()
-
◇ データアップロード
-
インポートファイル選択画面を表示します。
-
![]() 削除
削除
-
アップロードファイルを削除します。
※ データのアップロードが不要な場合は、読み飛ばして3を参照ください。
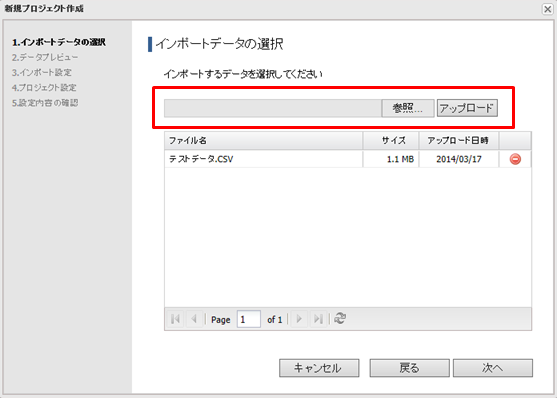
2.[データアップロード]ボタンをクリックすると表示します。
ファイルを選択して[アップロード]ボタンをクリックします。
![]()
ファイルのアップロードが完了するとファイルリストに追加され、選択が可能になります。
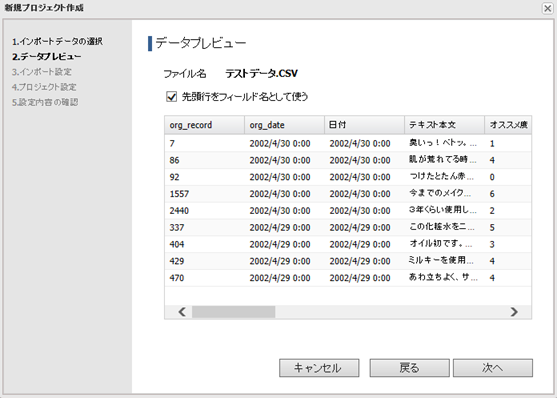
3.項目を設定して[次へ]ボタンをクリックします。
![]()
-
◇ 先頭行をフィールド名として使う
-
CSVファイルの先頭行をフィールド名として使用したい場合にチェックしてください。
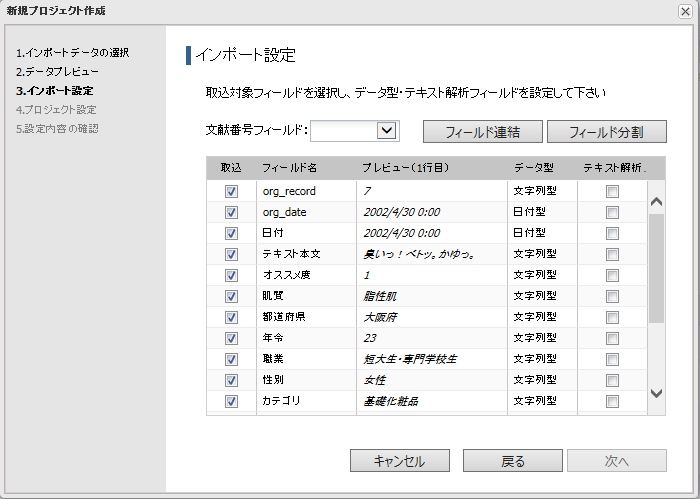
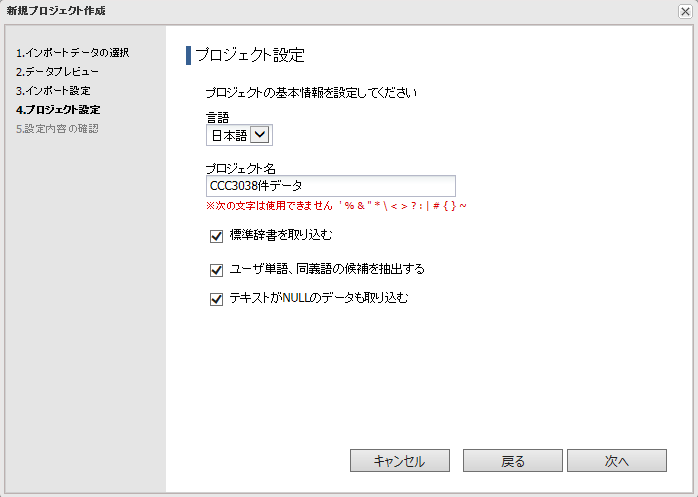
4.項目を設定して[次へ]ボタンをクリックします。
フィールド連結を設定する場合は[フィールド連結]をクリックします。
フィールド分割を設定する場合は[フィールド分割]をクリックします。
![]()
-
◇ フィールド連結ボタン
-
複数あるテキストフィールドを連結し、取り込みを行ないます。
-
◇ フィールド分割ボタン
-
1つのテキストフィールドを分割し、取り込みを行ないます。
-
◇ 文献番号フィールド
-
CyberPatent Deskと連係する際にキーとなる属性項目を設定します。
-
◇ データ型
-
データ型の指定をします。
-
◇ テキスト解析
-
テキストマイニングの対象とする文章情報を含むフィールドにチェックを入れます。
テキストフィールドは複数指定可能です。アンケートのフリーアンサーなど、
いくつかの項目の関係を分析したい場合は、複数チェックをしてください。
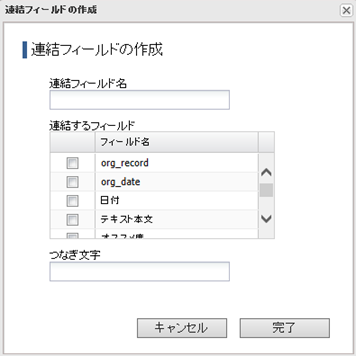
5.[テキスト連結]ボタンをクリックすると表示します。各項目を設定して[完了]ボタンをクリックします。
![]()
-
◇ 連結フィールド名
-
連結後のフィールド名を入力します。
-
◇ 連結するフィールド
-
連結するフィールドを選択します。
-
◇ つなぎ文字
-
フィールドを連結する際、つなぎ文字を挿入する場合に指定します。
連結箇所を分かりやすくしたい場合ご利用ください。
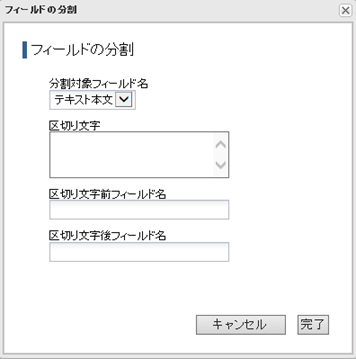
6.[テキスト分割]ボタンをクリックすると表示します。各項目を設定して[完了]ボタンをクリックします。
![]()
-
◇ 分割対象フィールド名
-
分割対象のフィールド名を選択します。
-
◇ 区切り文字
-
分割する区切り文字を入力します。
-
◇ 区切り文字前フィールド名
-
分割後の区切り文字より前の文字列を格納するフィールド名を設定して下さい。
-
◇ 区切り文字後フィールド名
-
分割後の区切り文字より後ろの文字列を格納するフィールド名を設定して下さい。
7.各項目を設定して[次へ]ボタンをクリックします。
![]()
-
◇ 標準辞書を取り込む
-
チェックを入れると、特許データ向けの標準辞書を取り込みます。
-
◇ ユーザー単語、同義語の候補を抽出する
-
プロジェクト作成時にユーザー辞書、同義語辞書の登録候補を抽出して登録します。
-
◇ テキストがNULLのデータも取り込む
-
テキスト解析フィールドに未記入のデータ(NULLデータ)がある場合、
そのレコードを取り込む場合にチェックしてください。
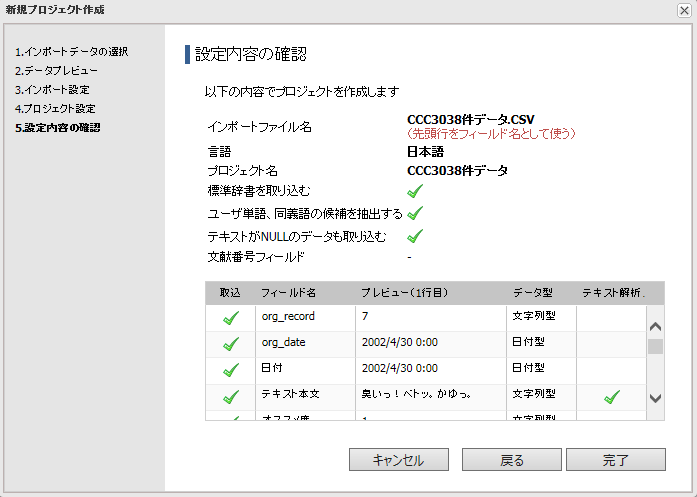
8.設定情報の確認を行い[完了]ボタンをクリックします。
![]()
以上でCSVプロジェクトの作成は完了です。